










Announcement
Welcome to my blog! This is a sample announcement.
438 字
2 分钟
Python网络爬虫_URL封装【5】
为了达到便于管理的目的,大多网站会对网页的URL地址采取封装措施。
URL封装
- 在我们访问网站时,通常会看到不一样的网址,就如豆瓣电影的动作片排行榜的网页路径一样。并不是一个很层级形式的路径。
- 这就是URL封装。
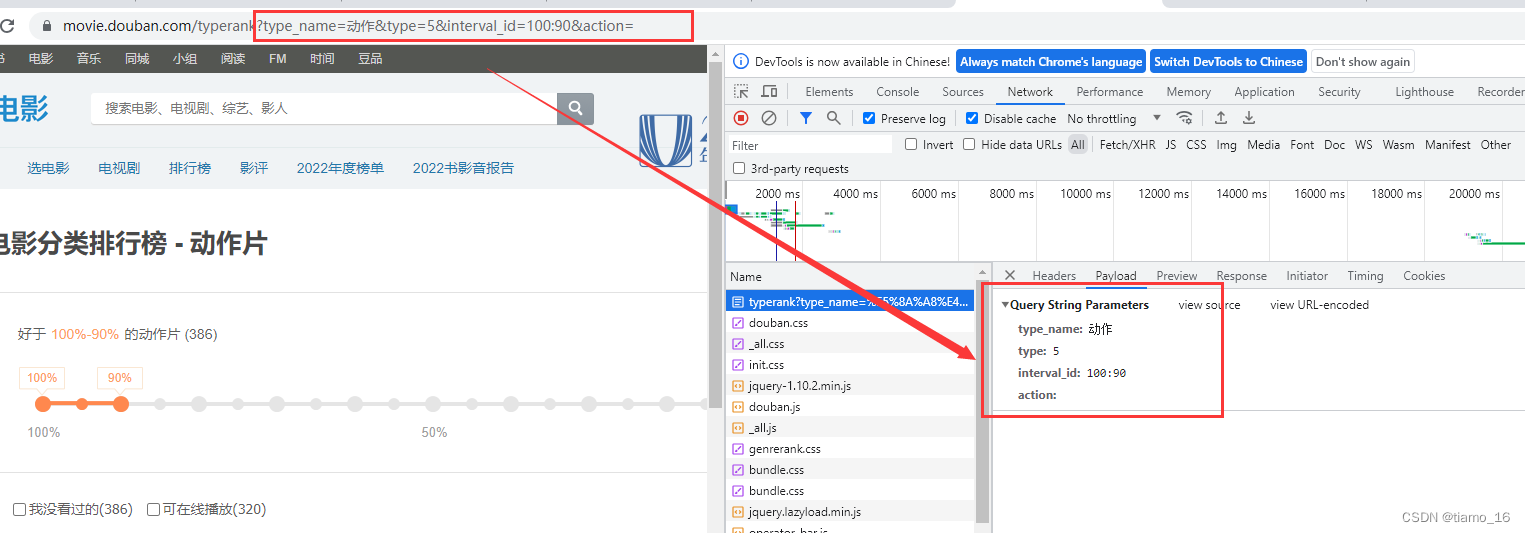
 3. 可以发现,URL路径中,从里面的问号开始往后就是封装的内容。
3. 可以发现,URL路径中,从里面的问号开始往后就是封装的内容。
 4. 像URL路径这样的,一般以Json的形式存在于请求的Request Payload,内参数用于指定路径。准确来说应该是一种请求体。
5. 我们打开检查查看Payload
6. 可以发现,Payload参数完全对应着URL的后半部分。
4. 像URL路径这样的,一般以Json的形式存在于请求的Request Payload,内参数用于指定路径。准确来说应该是一种请求体。
5. 我们打开检查查看Payload
6. 可以发现,Payload参数完全对应着URL的后半部分。
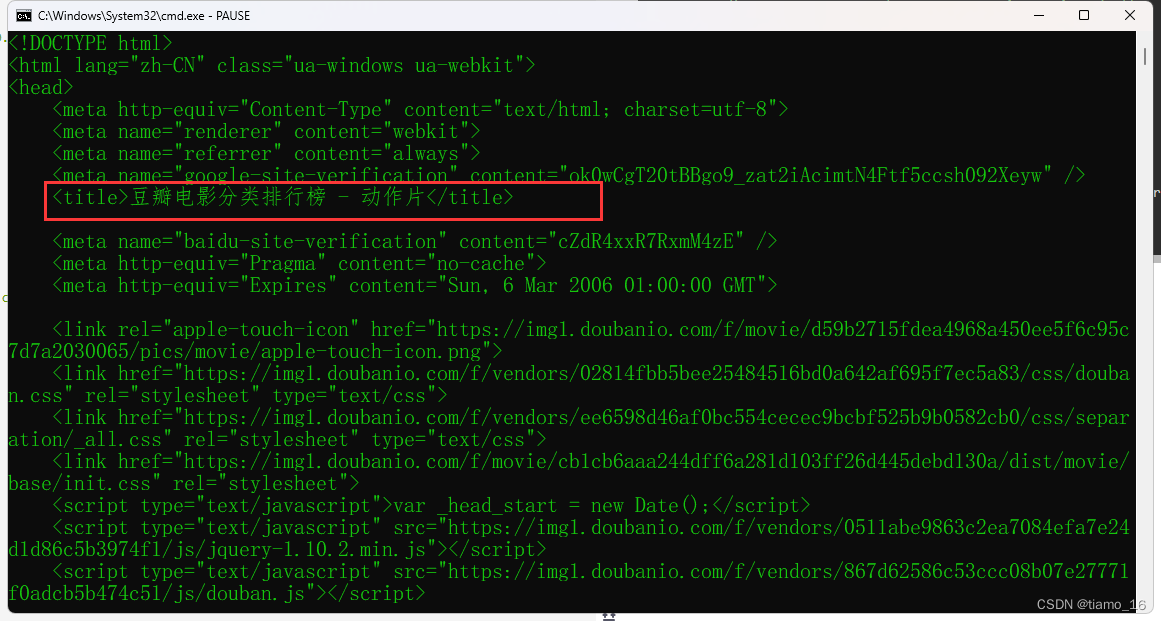
- 如果我们把这个Payload放入代码中拼接起来会咋样呢 因为像这样的参数我们需要将它们写成字典再传入Params可选参数,即可。
import requests # 导入请求库
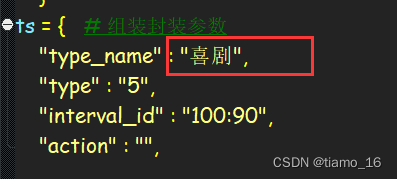
tou = { # 伪装浏览器 "User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36', }ts = { # 组装封装参数 "type_name" : "动作", "type" : "5", "interval_id" : "100:90", "action" : "",
}resposn = requests.get('https://movie.douban.com/typerank/', headers=tou, params=ts)
print(resposn.text) # 输出- 可以看到运行后,就获取到了和页面一模一样的豆瓣动作片排行榜的源代码, 这就说明,Payload就是经过拆解后的URL。
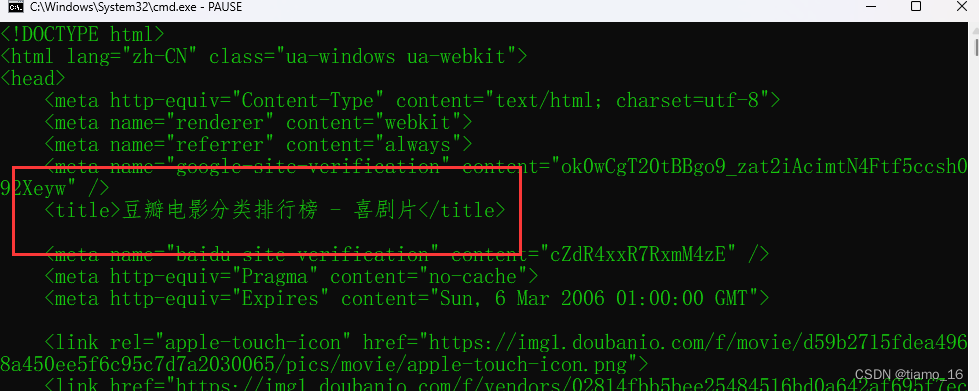
 9. 按照这样的思路,我们可以利用封装后的URL举一反三。
比如我们将参数修改一下,将动作换成戏剧,运行后我们就可以拿到豆瓣喜剧片的排行榜源码了。
9. 按照这样的思路,我们可以利用封装后的URL举一反三。
比如我们将参数修改一下,将动作换成戏剧,运行后我们就可以拿到豆瓣喜剧片的排行榜源码了。
1.内容为本人学习笔记,难免有不足之处,恳请大家批评指正。
Python网络爬虫_URL封装【5】
https://mizuki.mysqil.com/posts/python网络爬虫_url封装5/ 部分信息可能已经过时
